

1. مقدمه
میکروبیولوژی پیشبینیکننده رشتهای است که در تقاطع میکروبیولوژی و مدلسازی ریاضی قرار دارد و هدف آن پیشبینی رفتار میکروارگانیسمها در محیطهای مختلف است. در طول سالها، ظهور ML چشمانداز میکروبیولوژی پیشبینیکننده را متحول کرد و ابزارهای قدرتمندی برای مدلسازی و پیشبینی رشد، بقا و تعاملات میکروبی ارائه کرد. این مقاله کاربرد ML در میکروبیولوژی پیشبینی را بررسی میکند و روشن میکند که چگونه این تکنیکهای محاسباتی پیشرفته درک ما از دینامیک میکروبی را افزایش میدهند و به تضمین ایمنی مواد غذایی، سلامت محیط زیست و رفاه عمومی کمک میکنند. ML از الگوریتمهایی استفاده میکند که کامپیوترها را قادر میسازد الگوها را یاد بگیرند و بدون برنامهنویسی صریح از دادهها پیشبینی کنند. در حوزه میکروبیولوژی پیشبینیکننده، این قابلیت در مدلسازی پاسخهای میکروبی پیچیده یسته به عوامل محیطی مانند دما، pH و در دسترس بودن مواد مغذی بسیار مفید است. مدلهای سنتی اغلب بر فرضیات ساده و پارامترهای ثابت تکیه میکنند، در حالی که تکنیکهای ML میتوانند با مجموعه دادههای پویا و متنوع سازگار شوند و پیچیدگیهای رفتار میکروبی را تطبیق دهند. کاربرد ML در میکروبیولوژی پیشبینیکننده به حوزههای مختلفی از جمله ایمنی مواد غذایی، میکروبیولوژی بالینی و نظارت بر محیطزیست گسترش مییابد. در زمینه ایمنی مواد غذایی، مدلهای پیشبینی که توسط الگوریتمهای یادگیری ماشین هدایت میشوند، به ارزیابی خطر آلودگی میکروبی، هدایت تصمیمهای مربوط به پردازش، ذخیرهسازی و توزیع مواد غذایی کمک میکنند. علاوه بر این، این مدلها به توسعه استراتژیهای پیشگیرانه قوی کمک میکنند و در نهایت باعث کاهش بروز بیماریهای ناشی از غذا میشوند. در میکروبیولوژی بالینی، ML نقش اساسی در پیشبینی شیوع بیماریهای عفونی، بهینهسازی استراتژیهای درمان و درک پویایی جوامع میکروبی در بدن انسان دارد. این رویکرد بین رشتهای دانش میکروبیولوژیکی را با تکنیکهای محاسباتی پیشرفته ادغام میکند و درک جامعتری از تعاملات میکروبی در سیستمهای پیچیده بیولوژیکی ایجاد میکند. به طورکلی با استفاده از پتانسیل ML، میکروبیولوژی پیشبینیکننده از یک رشته ایستا به یک زمینه پویا و سازگار تبدیل میشود و توانایی ما را برای پیشبینی و کاهش تأثیر میکروارگانیسمها در محیطهای مختلف افزایش میدهد. این اکتشاف نشان دهنده سفری دگرگون کننده به سمت رویکردهای مؤثرتر و مناسب تر در مدیریت پویایی میکروبی به نفع سلامت عمومی و پایداری محیطی است. بنابراین باتوجه به اهمیت ML در ابتدا به بررسی تعریف و مفاهیم ML می پردازیم و سپس کاربرد آن را در میکروبیولوژی پیشگو بررسی می کنیم.
2. یادگیری ماشین (ML) چیست؟
اصطلاح Machine learning توسط آرتور ساموئل در سال 1959 ابداع شد، که ML را به عنوان یک رشته تحصیلی تعریف کرد که قابلیت یادگیری را بدون برنامهریزی صریح برای رایانهها فراهم میکند. به عبارت دیگر ML علم آموزش کامپیوترها برای یادگیری از داده ها و پیش بینی یا تصمیم گیری بدون برنامه ریزی صریح است.
3. انواع الگوریتم های یادگیری ماشین (ML)
1) یادگیری تحت نظارت (Supervised learning): نوعی یادگیری ماشینی است که در آن الگوریتم از داده های برچسب دار یاد می گیرد. به عبارت دیگر در یادگیری نظارت شده مدل را با ورودیها (ویژگیها) و خروجیهای (برچسبها) دادهها تطبیق میدهیم. در پایان ما انتظار داریم که مدل ما نزدیکترین خروجی های دنیای واقعی را برای مجموعه جدیدی از داده های ورودی پیش بینی کند.
کاربرد:
1. طبقهبندی: یادگیری تحت نظارت میتواند برای طبقهبندی دادهها به دستههای مختلف بر اساس مثالهای برچسبگذاری شده استفاده شود.
2. رگرسیون: همچنین می توان از آن برای پیش بینی مقادیر پیوسته بر اساس داده های برچسب دار استفاده کرد.
2) یادگیری بدون نظارت (Unsupervised learning): نوعی یادگیری ماشینی است که در آن الگوریتم از داده های بدون برچسب یاد می گیرد. هیچ خروجی خاصی برای یادگیری ندارد و در عوض الگوها یا روابط درون داده ها وجود دارد. از آنجایی که ما هیچ برچسبی برای خروجی مدل نداریم، باید نتایج خروجی را بیشتر تجزیه و تحلیل کنیم تا بتوانیم از آن استفاده کنیم.
کاربرد:
1. خوشه بندی: یادگیری بدون نظارت معمولاً برای کارهای خوشه بندی استفاده می شود، جایی که الگوریتم نقاط داده مشابه را با هم گروه بندی می کند.
2. کاهش ابعاد: همچنین برای کاهش ابعاد داده ها استفاده می شود که می تواند برای تجسم و انتخاب ویژگی مفید باشد.
3) یادگیری تقویتی (Reinforcement learning): نوعی یادگیری ماشینی است که در آن مدل به یک سیستم مبتنی بر هوش مصنوعی (گاهی اوقات به عنوان عامل از آن یاد میشود) اجازه میدهد تا از طریق آزمون و خطا با استفاده از بازخورد اقدامات خود یاد بگیرد.
کاربرد:
1. بازی
2. رباتیک
نکته مهم:
در برخی منابع نوع دیگری به نام یادگیری نیمه نظارتی (Semi-supervised learning) نیز ذکر شده است. یادگیری نیمه نظارتی بین یادگیری بدون نظارت (بدون هیچ گونه داده آموزشی برچسب گذاری شده) و یادگیری نظارت شده (با داده های آموزشی کاملاً برچسب گذاری شده) قرار می گیرد. در این نوع یادگیری داده های برچسب دار ارائه شده و با استفاده از یادگیری، درک و تفسیر داده های بدون برچسب انجام می شود.
4. فرآیند یادگیری ماشینی (ML)
1) جمع آوری و پیش پردازش داده ها
جمع آوری داده: جمع آوری داده های مرتبط و آماده سازی آن برای تجزیه و تحلیل بسیار مهم است. داده باید از کیفیت بالایی برخوردار بوده و معتبر باشند. همچنین تعداد داده ها اهمیت بسیاری دارد و معمولا تعداد بالای داده نتیجه بهتری ارائه می دهد.
پیش پردازش داده ها:
1. حذف نقاط پرت (Cleaning outliers)
2. نرمال سازی داده (Normalization)
3. جایگزینی مقادیر از دست رفته (Imputation of missing values)
4. مقیاس بندی ویژگی (Feature scaling)
5. مهندسی ویژگی (Feature engineering)
2) انتخاب و آموزش مدل
انتخاب مدل مناسب و آموزش آن با استفاده از داده های جمع آوری شده یک مرحله کلیدی است.
تقسیم داده ها: در میکروبیولوژی پیش بینی، آموزش و ارزیابی مدل با تقسیم داده ها به مجموعه های آموزشی (Train) و آزمایشی (Test) آغاز می شود. مجموعه آموزشی برای آموزش الگوریتم های یادگیری ماشین استفاده می شود، در حالی که مجموعه تست برای ارزیابی عملکرد مدل های آموزش دیده استفاده می شود.
الگوریتم های یادگیری ماشین: پس از تقسیم داده ها، الگوریتم های یادگیری ماشینی مناسب برای آموزش مدل ها انتخاب می شوند. این الگوریتمها میتوانند شامل درختهای تصمیم، جنگلهای تصادفی، ماشینهای بردار پشتیبان و شبکههای عصبی و ... باشند.
3) ارزیابی و استقرار مدل
ارزیابی عملکرد مدل آموزش دیده و به کارگیری آن در تولید ضروری است. در واقع پس از آموزش مدل ها، عملکرد آنها با استفاده از معیارهای مختلف ارزیابی می شود.
5. چالش ها و ملاحظات در یادگیری ماشینی (ML)
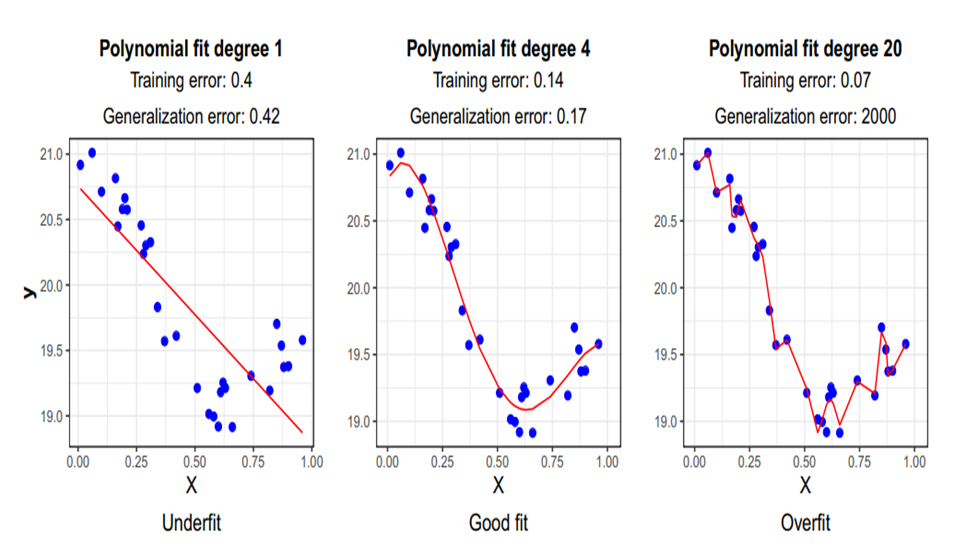
1) Overfitting & Underfitting:
Underfitting معمولا زمانی رخ می دهد که یک مدل بسیار ساده برای ثبت پیچیدگی داده ها استفاده شود. این عدم تناسب سبب ناتوانی در یادگیری می شود. جهت حل این مشکل میتوان از راه حل های زیر استفاده کرد:
1. استفاده از مدل های پیچیده تر و متناسب با داده
2. حذف نویز و نوسانات
3. افزایش تعداد دور و یا افزایش مدت زمان train
Overfitting معمولا زمانی رخ می دهد که برازش بیش از حد انجام شود. درواقع با داده های زیاد آموزش انجام می شود و تحت این شرایط یادگیری از نویز ها و input های نادرست انجام میشود.جهت حل این مشکل میتوان از راه حل های زیر استفاده کرد:
1. استفاده از الگوریتم های خطی ( در صورت داشتن داده های خطی)
2. افزایش تعداد داده
3. کاهش پیچیدگی مدل
2) Bias and Variance :
Bias: زمانی که از یک مدل ساده برای درک داده های پیچیده استفاده میشود، سبب می شود پیچیدگی های داده در بر گرفته نشود بنابراین رابطه واقعی بین input و output نشان داده نمیشود و این حالت مشابه با حالت Underfitting می باشد.
Variance: زمانی که نویز و نوسانات وجود داشته باشد و مدل نویز و داده های نادرست را جهت یادگیری استفاده کند سبب افزایش واریانس می شود و این حالت مشابه با حالت Overfitting می باشد.
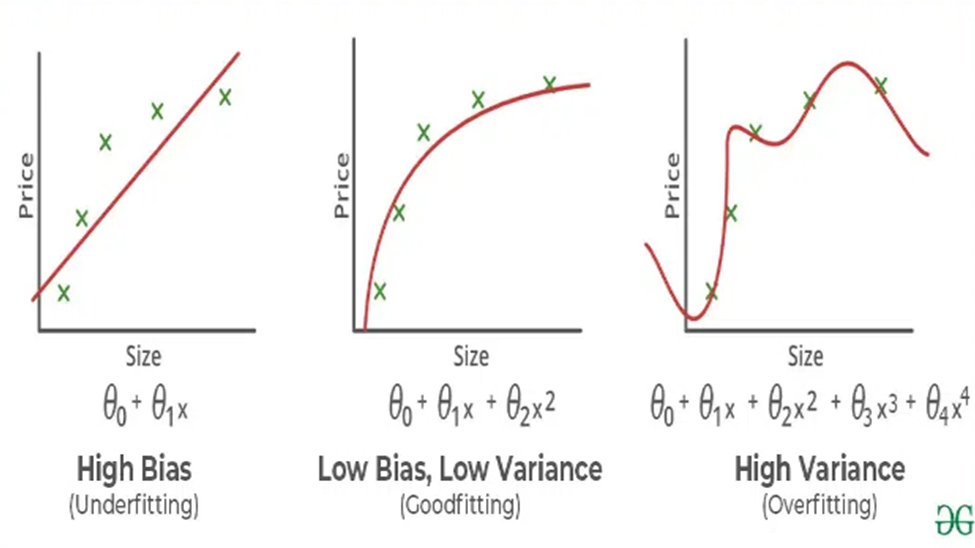
3) Data Quality and Quantity: مدل های یادگیری ماشینی به شدت بر مقادیر زیادی داده با کیفیت بالا متکی هستند. با این حال، به دست آوردن و مدیریت چنین داده هایی می تواند چالش برانگیز و زمان بر باشد.
6. کاربرد یادگیری ماشینی (ML) در صنایع غذایی
1)کنترل کیفیت و بازرسی
2) کشف تقلب در مواد غذایی
3) بهینه سازی فرمولاسیون و طعم
4) میکروبیولوژی پیش بینی کننده
5) تحلیل حسی
6) بهره وری انرژی
7) بهینه سازی زنجیره تامین
8) ایمنی و ردیابی مواد غذایی
9) تشخیص تقلب در برچسب گذاری مواد غذایی
10) پیش بینی تقاضا
11) کشاورزی دقیق
12) تحلیل روند بازار
همان طور که توضیح داده شد ML در صنایع غذایی کاربرد های بسیاری دارد. یکی از کاربردهای مهم آن در بخش میکروبیولوژی مواد غذایی در زمینه میکروبیولوژی پیشگو است. در ادامه به بررسی آن می پردازیم.
7. مقدمه ای بر میکروبیولوژی پیش بینی کننده
میکروبیولوژی پیش بینی کننده یا پیشگو رشته ای است که از مدل های ریاضی برای پیش بینی رشد و رفتار میکروارگانیسم ها در غذا استفاده می کند. با درک نحوه رفتار و تکثیر میکروارگانیسمها، میتوانیم خطر بیماریهای ناشی از غذا را بهتر ارزیابی کنیم و اقدامات پیشگیرانه را برای اطمینان از ایمنی غذا انجام دهیم.
میکروبیولوژی مواد غذایی پیشبینیکننده سنتی به مدلهای اولیه و ثانویه برای شبیهسازی نحوه رفتار میکروارگانیسمها در طول زمان و در شرایط مختلف محیطی متکی است. مدلهای اولیه، مانند مدلهای اصلاحشده گومپرتز، لجستیک، بارانی و هوانگ، معمولاً برای توصیف رفتار میکروارگانیسمها در شرایط محیطی سازگار استفاده میشوند. از سوی دیگر، مدلهای ثانویه، تأثیر عوامل محیطی و ویژگیهای غذا را بر پارامترهای مدل اولیه در نظر میگیرند.
8. چالش ها و محدودیت های مدل های ریاضی در میکروبیولوژی پیشگو
1)داده های با کیفیت بالا
پیشبینیهای دقیق بر مجموعه دادههای بزرگ و متنوعی تکیه میکنند که پیچیدگی رشد میکروبی و الگوهای بقا را نشان میدهند. با این حال، بهدلیل محدودیت منابع، نگرانیهای مربوط به حریم خصوصی دادهها و نیاز به پروتکلهای استاندارد جمعآوری دادهها، بهدست آوردن چنین دادههایی میتواند چالش برانگیز باشد.
2) به روز رسانی مداوم مدل
جمعیت میکروبی و رفتار آنها می تواند در طول زمان به دلیل عوامل مختلفی مانند شرایط محیطی، جهش های ژنتیکی و تعاملات میکروبی تغییر کند. بنابراین، مدلهای پیشبینی باید مرتباً بهروزرسانی شوند تا این تغییرات در نظر گرفته شود و دقت آنها حفظ شود.
3) داده های ورودی دقیق
یکی از چالش های کلیدی در میکروبیولوژی پیش بینی نیاز به داده های ورودی دقیق و قابل اعتماد است. این شامل دادههای مربوط به نرخ رشد میکروبی، نرخ بقا و سایر عواملی است که بر رفتار میکروبی تأثیر میگذارند. بدون داده های دقیق، پیش بینی های انجام شده توسط مدل ها ممکن است قابل اعتماد نباشد.
4) محدودیت های مدل های فعلی
مدل های پیش بینی کنونی در میکروبیولوژی دارای محدودیت های خاصی هستند که باید در نظر گرفته شوند. این مدلها اغلب بر اساس فرضیات سادهسازی شدهاند و ممکن است پیچیدگی رفتار میکروبی را بهطور کامل نشان ندهند. علاوه بر این، مدلها ممکن است تمام متغیرها و عواملی را که میتوانند بر رشد و بقای میکروبی در سیستمهای غذایی مختلف تأثیر بگذارند، در نظر نگیرند.
بنابراین این چالش ها و محدویت ها سبب گام برداشتن محققین به سمت استفاده از روش های نوین مانند ML به عنوان جایگزین مدل های ریاضی قدیمی گردید.
9. کاربرد یادگیری ماشینی (ML) در میکروبیولوژی پیش بینی کننده
1) ایمنی مواد غذایی: ML به پیشبینی و پیشگیری از شیوع بیماریهای ناشی از غذا با ارزیابی ریسک میکروبی بهبودیافته کمک میکند.
2) پیش بینی فساد: مدلهای ML به پیشبینی الگوهای فساد و بهینهسازی کیفیت و ماندگاری محصول کمک میکنند.
3) بهینه سازی فرآیند: ML به بهینهسازی پارامترهای پردازش برای کنترل آلودگی میکروبی و تضمین ایمنی محصول کمک میکنند.
در نهایت باتوجه به توضیحات مطرح شده به بررسی مثالی می پردازیم:
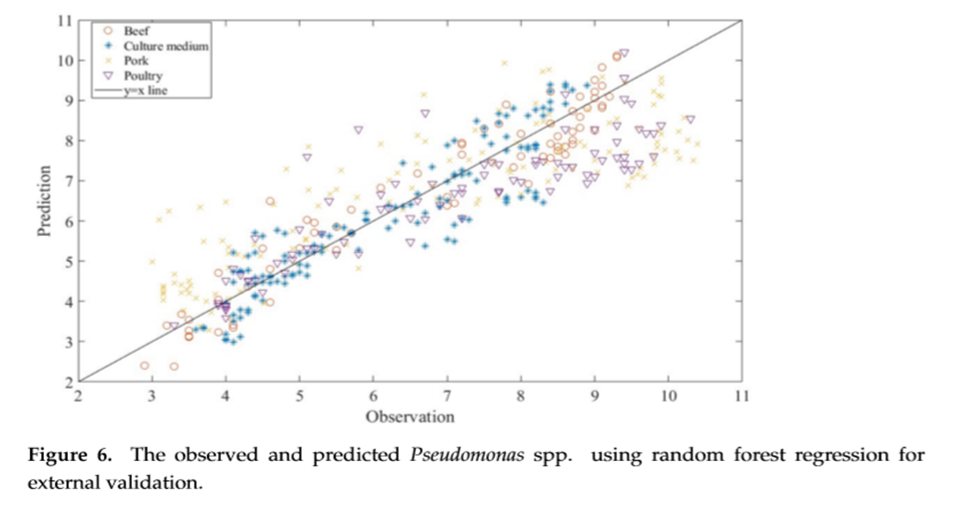
محققین (2023) در پژوهشی با هدف پیش بینی جمعیت گونه های سودوموناس در محصولات غذایی و محیط کشت از روش های رگرسیون مبتنی بر یادگیری ماشین استفاده کردند. در این پژوهش 4 الگوریتم زیر مورد استفاده قرار گرفت و بهترین الگوریتم جهت مدلسازی انتخاب شد:
1.Support vector regression (SVR)
2.Gaussian process regression (GPR)
3.Decision tree regression (DTR)
4.Random forest regression (RFR)
به منظور دستیابی به داده های مورد نیاز، در مجموع 5618 نقطه داده برای گونه های سودوموناس موجود در محصولات غذایی (گوشت گاو، گوشت خوک، و طیور) و محیط های کشت از پایگاه داده ComBase جمع آوری شد و سپس الگوریتم های ML برای پیش بینی رفتار رشد یا بقای گونه های سودموناس در محصولات غذایی و محیط های کشت با در نظر گرفتن متغیرهای پیش بینی کننده مانند دما، غلظت نمک، فعالیت آب و اسیدیته استفاده شد.
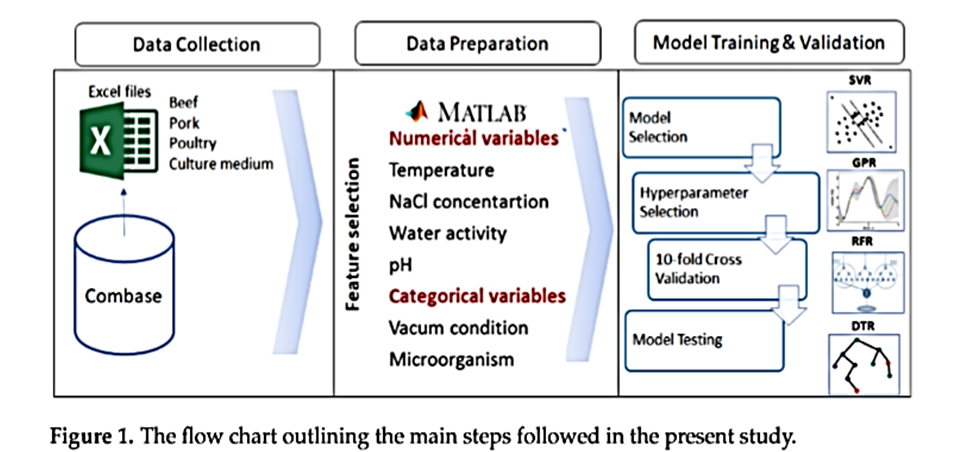
در نهایت جهت validation مدل ها از دو روش Hold-out validation process و k-fold cross validation process استفاده شد.
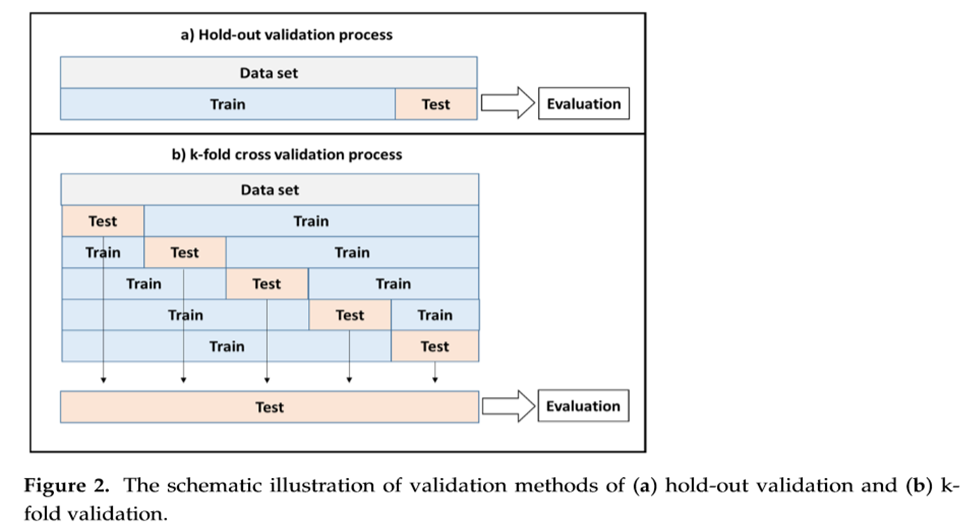
به طور کلی همیشه بهتر است از تکنیک k-fold به جای Hold-out استفاده شود. K-fold نتایج پیشبینی با ثباتتر و قابل اعتمادتری را ارائه میدهد زیرا فرآیندهای آموزش و آزمایش در چندین بخش مختلف مجموعه داده انجام میشوند. از طرف دیگر، روش Hold-out شامل تقسیم یک مجموعه داده به 20-30٪ داده های آزمایشی و بقیه به عنوان داده های آموزشی است. این اعداد میتوانند متفاوت باشند - درصد بیشتری از دادههای تست، مدل را مستعد خطا میکند زیرا تجربه آموزشی کمتری دارد، در حالی که درصد کمتری از دادههای تست ممکن است به مدل سوگیری ناخواسته نسبت به دادههای آموزشی بدهد. این عدم آموزش می تواند منجر به عدم تناسب بیش از حد مدل شود.
در نهایت نتایج نشان داد روش Random forest regression (RFR) نرخ خطای کمتر و نتایج بهتری را نشان می دهد.
10. نتیجه گیری
در نتیجه، استفاده از ML در میکروبیولوژی پیش بینی کننده نشان دهنده یک جهش دگرگون کننده در توانایی ما برای اطمینان از ایمنی و کیفیت مواد غذایی است. ادغام مدلهای محاسباتی پیشرفته، توسعه ابزارهای پیشبینی دقیقتر و کارآمدتر را برای رفتار میکروبی در سیستمهای غذایی امکانپذیر کرده است. از طریق تجزیه و تحلیل مجموعه دادههای گسترده و الگوهای پیچیده، الگوریتمهای ML قابلیتهای پیشبینی بینظیری را ارائه میدهند که به ارزیابی ریسک، پیشبینی فساد و کنترل بیماریزا کمک میکند. به عبارت دیگر دقت و مقیاسپذیری ML رویکرد فعالتر و پاسخگوتر به چالشهای میکروبیولوژیکی در صنایع غذایی را تسهیل کرده است. این ابزارها متخصصان ایمنی مواد غذایی را برای پیشبینی و کاهش مشکلات بالقوه توانمند میسازند و احتمال رویدادهای آلودگی را کاهش میدهند و ایمنی کلی محصول را افزایش میدهند.
در ادامه در ویدئو زیر در قالب مثالی فرضی به نحوه کار با جعبه ابزار Machine Learning در نرم افزار متلب جهت مدل سازی و پیش بینی می پردازیم.


